
Abstract
While Online Publishing has replaced most traditional printed journals in less than twenty years, today’s Online Publication Formats are still closely bound to the medium of paper. Collaboration is mostly hidden from the readership, and ‘final’ versions of papers are stored in ‘publisher PDF’ files mimicking print. Meanwhile new media formats originating from the web itself bring us new modes of transparent collaboration, feedback, continued refinement, and reusability of (scholarly) works: Wikis, Blogs and Code Repositories, to name a few. This chapter characterizes the potentials of Dynamic Publication Formats and analyzes necessary prerequisites. Selected tools specific to the aims, stages, and functions of Scholarly Publishing are presented. Furthermore, this chapter points out early examples of usage and further development from the field. In doing so, Dynamic Publication Formats are described as a) a ‘parallel universe’ based on the commodification of (scholarly) media, and b) as a much needed complement, slowly recognized and incrementally integrated into more efficient and dynamic workflows of production, improvement, and dissemination of scholarly knowledge in general.
We are Wikipedians. This means that we should be: kind, thoughtful, passionate about getting it right, open, tolerant of different viewpoints, open to criticism, bold about changing our policies and also cautious about changing our policies. We are not vindictive, childish, and we don’t stoop to the level of our worst critics, no matter how much we may find them to be annoying. Jimmmy Wales ― one of the founders of Wikipedia
Introduction
The knowledge creation process is highly dynamic. However, most of current means of scholarly publications are static, that means, they cannot be revised over time. Novel findings or results cannot contribute to the publications once published, instead a new publication has to be released. Dynamic publication formats will change this. Dynamic publication formats are bodies of text / graphic / rich media that can be changed quickly and easily while at the same time being available to a wide audience.
In this chapter we will discuss dynamic scholarly publication formats with respect to their chances, advantages, and challenges. First, we begin with a revision of existing and past publishing concepts. We discuss how the growing body of scholarly knowledge was updated and evolved using static forms of publishing. This will be followed by a structured analysis of the characteristics of dynamic publication formats, followed by a presentation of currently implemented solutions that employ concepts of dynamic publications.
Historic Dynamic Publishing Using Printed Journals and Books: Revising Editions or Publishing Novel Books and Articles
For centuries scholarly books were improved and updated with new content. This happened through releasing new editions. In subsequent editions, mistakes were corrected, recent results incorporated, and feedback from the readership used to improve the overall book. A sufficient demand for the reprinting of editions was a necessity. Before reprinting the publisher invited the author to revise the next edition (‘revised editions’1). The changes were usually marked and introduced in the preface of the consecutive editions.
Many encyclopedias, handbooks, and schoolbooks became established brands, which have been revised over and over again, sometimes over the space of decades. In many examples the authors changed. In successive revisions parts were changed, paragraphs rewritten, and chapters removed or added. In particularly vivid fields a different ‘genre’ of book—the loose-paper-collections—were invented. Here, carefully revised pages were sent out to subscribers on a regular basis.
Libraries provided not only access to the most recent version of books, but also kept earlier editions for interested readers. Earlier editions were of historical and epistemological interest.
Recurrent book editions made it necessary to add the consecutive edition number when referencing revised books.
Revising books allowed authors to keep track with novel developments. A book usually presented a closed ‘body of knowledge’, a mere collection of indisputable knowledge, often with a review character. Textbooks or encyclopedias were specially structured books.
In contrast to books, scholarly articles were a snapshot of certain scientific knowledge. In most scholarly fields, research results were published only once. Scientific journal articles were not to be revised—if new findings occurred, new articles were published. Publishing became the currency of research and around the journal article methods to measure the performance of researchers were developed.
The scholarly journal article and its ‘life cycle’ are currently under debate and development. New mechanisms to publish scientific results are being widely discussed; most opportunities have been opened up by the new possibilities that were enabled by the Internet.
Some of the most prominent changes that have already found wide acceptance so far are being reviewed in the following:
Preprint, Postprint and (Open) Peer Review
The fundamental interest of researchers is to publish their research results in a straightforward fashion. This is in conflict with the publishers’ duties of filtering good research from faulty research, rejecting papers with methods that are insufficient to draw the stated conclusion, or denying research publication that are out of the scope of the journal’s audience. The current gold standard supporting editorial decisions is the peer-review process as organized by the publishers. Since the peer-review process takes a significant amount of time and is one of the main causes of delaying publications, some research disciplines developed a culture of publishing so-called preprints‘’’. ’’’Preprints are preliminary, pre-peer-review versions of original research articles which are submitted to repositories such as arXiv (arxiv.org). It is acceptable to exchange preliminary versions with updates, for example updates with applied changes that occur during peer-review, but older versions are always available and cannot be removed. A publication identifier points to the most recent version of the article, but older versions can be assessed through a history function. Preprints are legally accepted by most journals. Some journals even combine the acceptance with preprints together with an open peer-review process in which all comments and changes can be tracked (Pöschl 2012). Postprints are versions of the article which are published after peer-review, usually by storing the article in repositories (see Chapter 09, Sitek et. al: Open Access: A State of the Art) or by sending them via email. They contain all the changes that have resulted from discourse with the peer-reviewers.
Follow-Ups and Retractions
Publishing preprints, postprints, or even the peer-review process allows the tracking of the development of a final version of a scholarly article. Usually, after peer-review, a final version of an article exists which must not be further changed.
After publication of the article, it is of interest to see how the article is being received by the community. Its impact is measured by counting the amount of citations to it, references which result at article-level (see chapter 12, Fenner et al: Altmetrics and other measures for scientific impact). Databases such as the Web of Science, Scopus, Google Scholar, ResearchGate, and non-commercial services such as Inspire count these citations and provide more meta-analysis of articles. References to the article are visible and so follow-up articles can be identified. Current databases do not give information about the context of a citation. It remains unclear as to whether the article is referenced as a citation within the introduction, a reference to similar ‘Material and Methods’, or whether the cited article is being disputed in the discussion.
In cases of scientific misconduct, articles are retracted. Obviously, this happens more and more often (cf. Rice 2013). Similarly, universities retract dissertations and other scientific publications. Obviously, printed or downloaded articles cannot disappear in the same way that online version of articles can be deleted. Libraries and repositories keep the retracted books, articles, or dissertations in the archives and just change the catalogue status to ‘retracted’. Publishers delete the online version and books are no longer sold.
Current Aspects of the Publication System in Regard to the Dynamic Knowledge Creation Process
The production process is not visible to the reader
With the advancement of the Internet, methods to cooperatively compile a text (‘collaborative authoring tools’) are finding wider application. It is now possible to trace each individual’s contribution to a text. Technically, it would be possible to track all versions and comments that occur during the production process. Currently, final versions of scholarly publications do not contain traces of their production process. The final version of a publication is a kind of finalized consent from all its authors without any traces of the production process itself.
The contribution of individual authors is not visible
Usually contributors to a scientific publication are stated in the list of authors. Large research organizations provide guidelines on the requirements to qualify as an author of an article. Only contributors should be listed as authors and there exist guidelines of good scientific practice so as to clarify what acceptable contributions are. Honorary authorships, e.g. authorships that are based on political considerations, are not considered appropriate2. The listing itself happens independently of the quantifiable amount of actual text contribution. However, often the placement and order of the authors give a hint on the amount and of the kind of contribution. Various cultures exist; in many disciplines (e.g. life sciences) the first and the last authors contributed most significantly to an article.
The distribution of third party funding is more and more based upon scientometric measurements which depend on authorship. Since the incentives are set that way, it is now very important to a researcher to have his contribution appropriately acknowledged. In this context, conventions on the good scientific practice guiding authorship qualifications have become much more important than in earlier times. This is especially true in the context of growing author lists and increasing manipulations. In practice, the distribution of authorship positions is a complex process, often involving a non-transparent system of social and professional dependencies.
Finalized versions do not allow changes, thus making corrections and additions nearly impossible
Despite the fact that the Internet allows for other procedures, the publication of a scholarly manuscript is organized around the release date of the publication. After the release of a scientific publication no corrections, additions, or changes are possible. Only in strong cases of scientific misconduct, falsicification or manipulation of findings will a retraction occur, usually with sweeping consequences for the authors in question. Minor mistakes cannot be corrected. Only a couple of journals provide online commenting functionality and these are not currently being used in a relevant matter. However, this might change quite soon, for example by merging in trackback functions as already used by weblogs. A scientific discourse around a publication cannot occur, and if so, channels such as comments or discussion forums are being used which are currently not credited. Only the discussion sections of new peer-reviewed publications are a chance for accredited scholarly criticism.
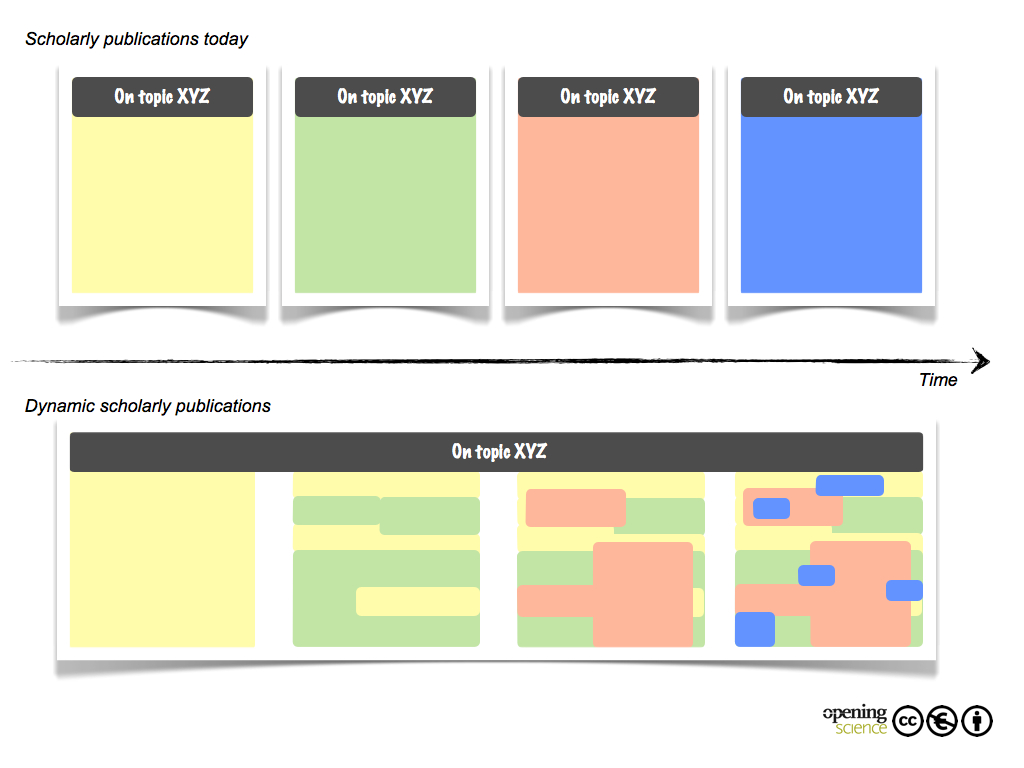
Redundancy in scientific publications—currently no reuse and remixing
The scientific knowledge creation process is usually incremental. Once a certain amount of scientific knowledge is gathered, a novel publication is released. Depending on discipline, a full paper, thesis, or book is the most accepted form of publication. Each release is considered to be a self-contained body of text, understandable to fellow-scientists in the field. This makes redundancy in the introduction, material, and methods a necessity. With this come certain legal and ethical implications. The authors are currently in danger of not only being accused of self-plagiarism, but also of copying from fellow scientists. Even if sections are correctly referenced and citations are placed, many scientists reword phrases for fear of being accused of plagiarism and scientific misconduct. Current conventions prevent scientific authors from reusing well-worded introductions or other paragraphs, despite the fact that from a truly scientific point of view, this would be totally acceptable if enough new content and results besides the copied and reused parts is present (Figure 1). Also, obvious remixing‘’’ ’’’of phrases and content from several sources is currently not accepted (Figure 2). This results in unnecessary rewording, a greater workload, and potentially sub-optimal phrasing. The same introduction, methodology description, and statements are rewritten over and over again, making it sometimes difficult to identify the truly new contribution to a scientific field (Mietchen et al. 2011). It is important to notice that in many disciplines and scientific cultures, mainly humanities, textual reproduction with precious words and in a literary manner is a considerable feat which is beyond the pure transportation of information. Here, the reusing and remixing of content has to be seen in a different context.
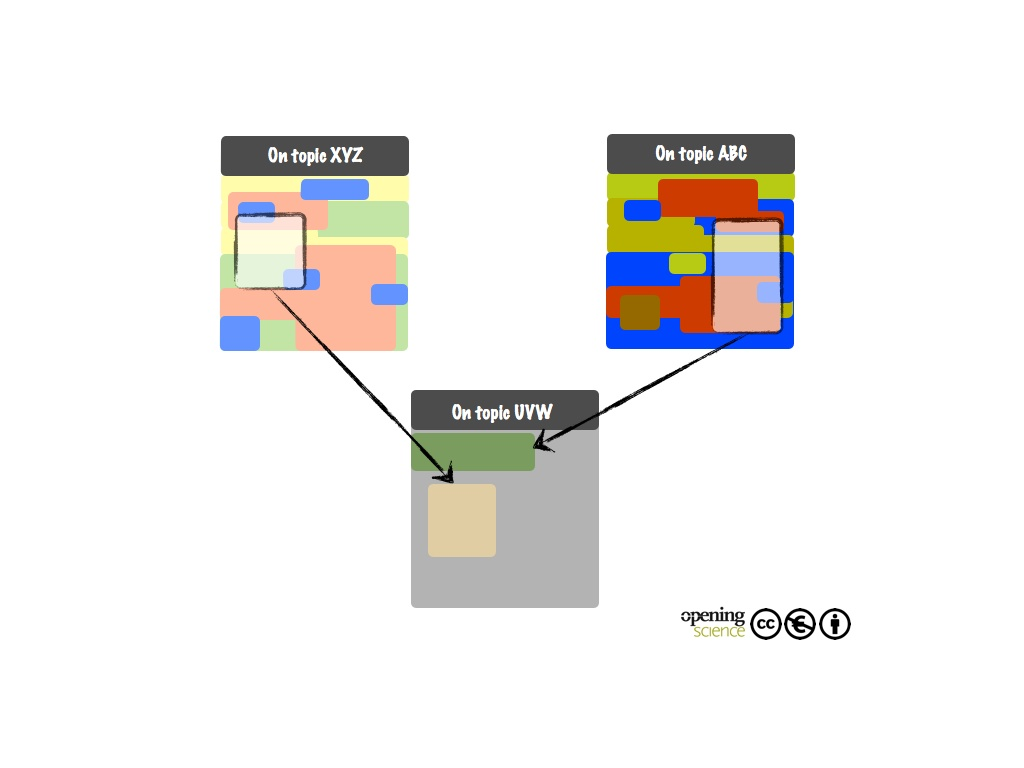
Legal hurdles to make remixing and reuse difficult
Most publishers retain the copyright of a publication, which strictly limits the reuse of text, pictures, and media. This banishment of remixing seems outdated in the age of the Internet. Novel copyright concepts such as Creative Commons (CC-BY) (see chapter 19, Friesike: Case: Creative Commons) will change this and will make reuse and remixing possible.
Technical hurdles in reusing content—“Publisher PDF” files are mimicking print
Some scientific publications are being reproduced in a way that makes the reuse of articles and parts of articles technically difficult. Sometimes, the PDF version is the only available version of an article. More open formats, such as HTML, XML, LaTeX source code, or word documents are not always released and remain with the publisher. Even the author themself suffers from significant hurdles in accessing the final version of his or her personal publications (cf. Schneider 2011; Wikiversity3).
The current publication system is a consequence of a scholarly knowledge dissemination system which developed in times before the Internet when printing and disseminating printed issues of papers were the only means of distributing scientific results. The Internet made it possible to break with the limitations of printed publications and allowed the development of dynamic publication formats.
Dynamic Publication Format — General Concept
Science as a whole is constantly developing. Novel insights, results, and data are permanently being found. The prevailing current publication system is dynamic, but its changes and iterations are too slow. The publication system developed long before the Internet. With the Internet came new possibilities for publishing, transporting results, and defining the nature of ‘a publication’. Dynamic publications can adapt to the development of knowledge. Just as Wikipedia is developing towards completeness and truth, why not have scientific publications that develop in pace with the body of scientific knowledge?
Dynamic publication — challenges
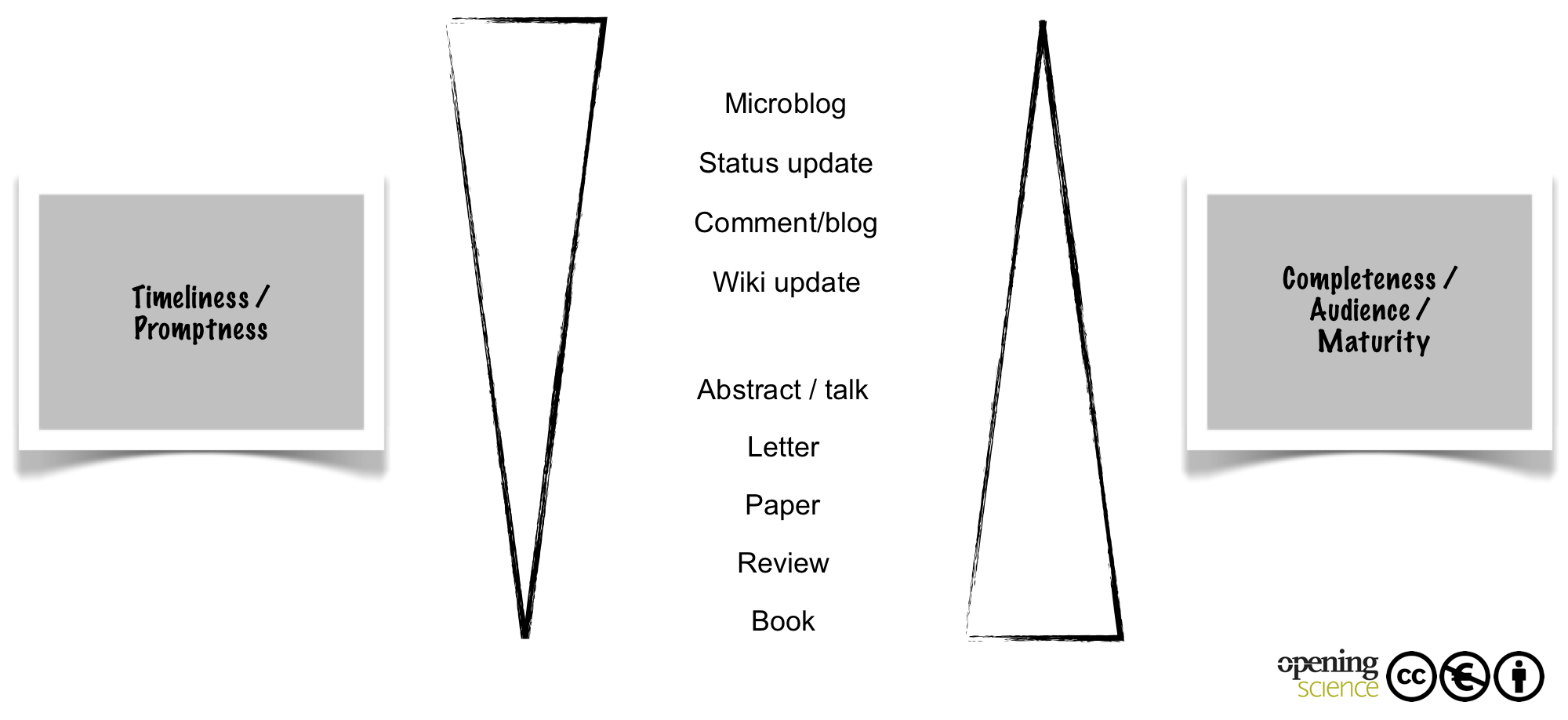
In the past a modality of publication was mainly shaped by the prevailing medium (paper) and its distribution (mailing). New scientific results had to cross a certain threshold to be publishable. This threshold was defined by the amount of effort that was necessary to produce this publication and to distribute it. A publication had to be somewhat consistent and comprehensible by itself. The forms of publications that were available in the past are abstracts, talks, papers, reviews, and books (Figure 3).

Since the Internet, the available publication methods are no longer limited to this list. It became possible that virtually everybody can publish at very little or no cost. The limiting factor of the medium of paper and its distribution vanished. Novel publication methods such as blogs, microblogs, comments, wiki updates, or other publication methods complement the prevailing publishing methods (Figure 4) (Pochoda 2012).
Aspects of Dynamic Publication Formats
Dynamic
Dynamic publication formats are—as the name says—dynamic (Figure 5), meaning that no static version exists. Dynamic publications evolve. The changes can be done on several formal levels, from letters and single words (‘collaborative authoring tools’, ‘wikis’), to a few sentences (‘status updates’) and whole paragraphs (‘blogs’, ‘comments’). Changes include deletions, changes, and additions. However, implementations vary in terms of how permanent a deletion may be.
Authorship
In collaborative authoring tools it is quite technically easy to precisely trace who typed which text and who drew which figures. However, authorship in a scientific publication currently represents much more than just an actual textual contribution. It defines whose ideas and theories lead to it, in addition to the actual work that was necessary to gather the scientific results. This is not adequately represented by the actual contribution of the text. Authorship is a guarantor of quality and here the personal reputation of a researcher is at stake. Therefore, clear statements of the kind of contribution to a work provided by an author should be associated with a publication. For example, many scientific journals request a definition of the role each author played in the production process of the work. The contributions range from the basic idea and actual bench work to revision of the article.
Openness
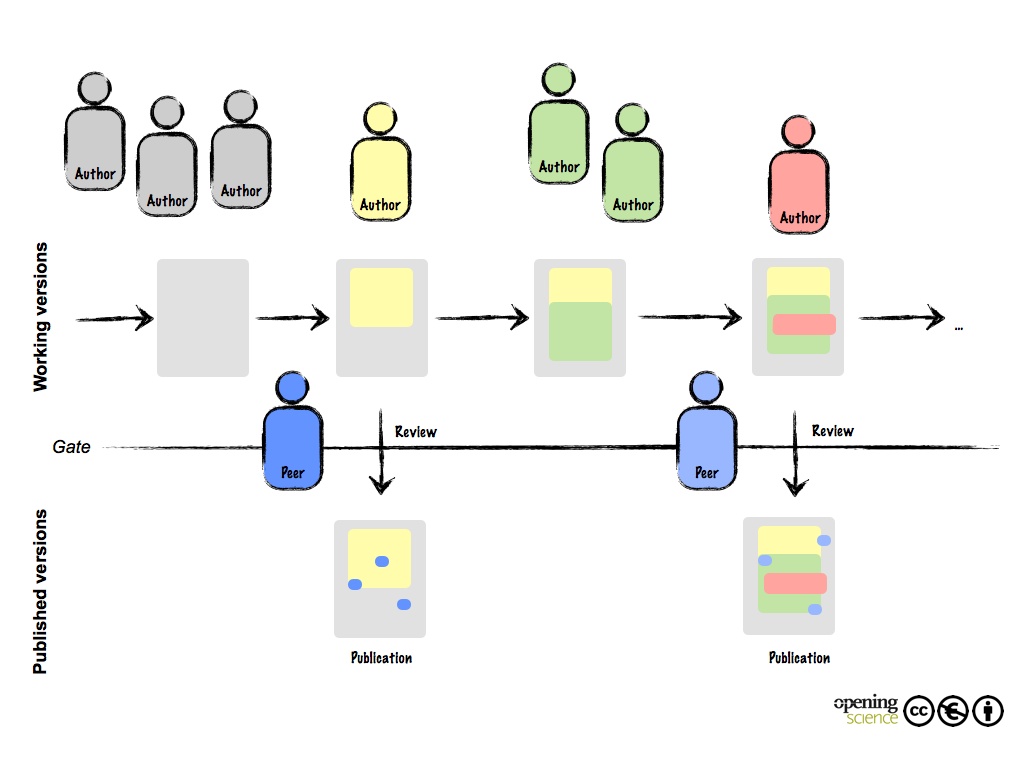
Technically the whole textual creation process including all typing and editing could be open. Furthermore, all commentary and discussion can be open. Certain consequences are related to such openness. Not all versions of a document and discussions are meant to be public. While openness can be seen as a tool for assuring quality and preventing scientific misconduct, at the same time it puts researchers under great pressure. Usually early versions of documents are full of spelling mistakes and errors and not meant to be seen by the public; furthermore, they usually lack approval from all coauthors.
A possible solution allows for some parts of the publication and editing process to take place with limited visibility in a working version. After all authors have approved a version or a revision, this version can become part of the public version (Figure 5). The step from working version to public version would be based on some internal ‘gatekeeping’ criteria, such as the discussion and consent of all authors, making the process similar to that of the peer-review process. However, the peer-review is done by people other than the authors themselves and the peer-reviewing process can be organized by a quality-granting authority such as a journal.
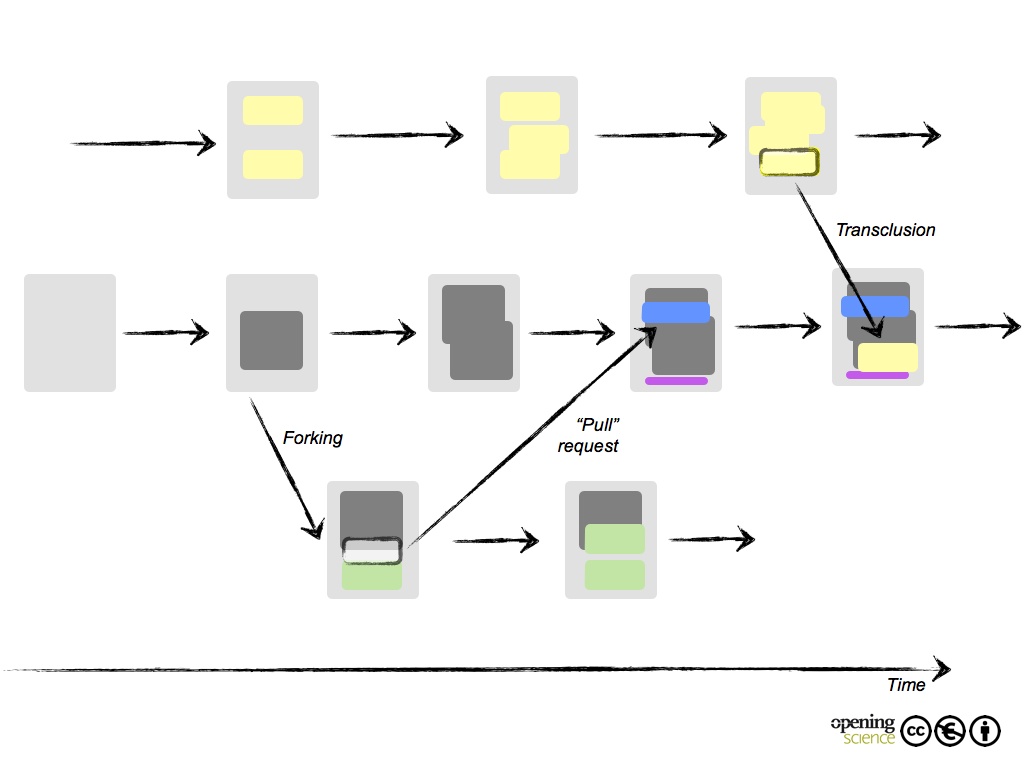
Tranclusion, pull-requests, and forking—Lifecycle and history
The lifecycle of a dynamic publication is much harder to define than the life cycle of a static, traditional publication. Concepts such as ‘transclusion’4, ‘pull-requests’, and ‘forking’5 allow for different kinds of remixing and ‘reuse’ of earlier publications (Figure 6). An important feature of dynamic publications is the availability of a history functionality so that older versions of the publication are still available and referencing to the older versions can occur. This might not only be of interest to historians of science, but may also be very valuable in assessing the merits of earlier scientific discoveries and documenting scientific disputes.
Many of these remixing and reuse concepts stem from collaborative software development and many of these are in turn far removed from the current perception of the life cycle of scientific publications. It remains to be seen whether they can be integrated into the scientific publishing culture so that the systems in question benefit from it, and usability, as well as readability, can be assured.
Publication formats
Various publication formats exist. There are books, chapters, abstracts, tweets, reviews, full-papers, and so on. Some publication formats are more likely to benefit from the many remixing concepts of dynamic publications than others. In many science cultures, reviews are constantly being released on similar topics, sometimes on an annual basis. A dynamic publication concept would be ideally suited to providing reviews of current developments: instead of publishing completely novel reviews, reviews could constantly be updated.
Content and quality control
The authors as the primary guarantors of quality remain untouched by the concepts of dynamic publications. However, while the pre-publication peer-review of static publications and the decision of editorial boards or publishers assured content in the past, this is more flexible in dynamic publications. An open commenting functionality can be seen as a form of post-publication review. The public pressure that is associated with potentially unmasking comments urges the authors to provide a high standard of output. If the commenting functionality is anonymous it should be clear to all readers that non-qualified comments may occur; at the same time, an anonymous commenting functionality may encourage true criticisms.
In actual implementations of dynamic publications, visibility of transclusions as well as pull-requests has to be assured—otherwise misunderstanding of the actual authorship may occur.
Cultural background
Dynamic publications are a completely novel tool in scholarly publishing. Scientists have to learn to use them and to understand their benefits and limitations. Furthermore, scientometrics have to learn how to assess contributions that occur in dynamic publications.
Some research fields are more suited to dynamic publication concepts, while others are less so. There are research cultures that might implement dynamic publications faster than others. Hard sciences/lab sciences are more suited for dynamic publications. Here, often novel, incremental findings just require small changes to a text, whereas in humanities comprehensive theories and interpretations might not be as suitable to be expressed in well-circumscribed changes of text.
Current Implementation of Dynamic Publications
Traditional scholarly publication methods exist – and novel tools and platforms that technically allow the realization of dynamic publication concepts have originated from the web. Tools that implement aspects of dynamic publishing are presented here and in Table 1 and their limitations explained.
Journal Articles and Books
Journal articles and books represent the gold-standard of scientific publishing. In the world of books and journal articles there exists a point in time that clearly divides the production phase from the reception phase of a scientific publication. This point in time is when the publication is released and available to readers. With this comes the expectation that the results and discussion of released scientific results provided are ‘complete’ and ‘final’. When the neutral and often anonymous peer-review process is finished, a publication is ‘fit to print’6. In most scientific cultures, it is not expected that something should be published before the peer-review is concluded. The production process is usually only open to the work group and authors. This is being changed through the use of Preprint-Repositories (like arXive.org (since 1991)), or the opening of the peer-review process in some journals (cf. Pöschl 2012). After peer-review critical comments, extensions, hints, and reviews have to go to other publications.
Blogs
Blogs are fundamentally different: Only the author decides on the medium, the structure of publication, and the point in time of the release. Usually blogs are produced by single persons and even in the case of blogging platforms the responsibility for the content of one blog usually rests with the author of that explicit blog. This results in certain expectations with respect to the content of the blog. In typical scientific blogs, scientists publish reviews and review-like aggregations of already published scientific publications. Blogs can often be seen as a method of science journalism. On the other hand, some scientists blog about their ongoing research, e.g. about the progress of a doctoral thesis (cf. Efimova 2009). In some cases a blog is a public form of the scientific knowledge creation process—the blog becomes a diary of the personal knowledge creation process, with novel ideas and results being constantly published. Even preliminary results and unproven hypotheses can be presented to a limited audience (limited in terms of real readers—most blogs are indeed completely open) which, on the other hand, provides useful feedback in the form of comments or other feedback. In this context, a blog post is usually based on earlier blog posts and it is not considered to be a ‘full publication’ with sufficient background information. A high level of very specialized knowledge is assumed (also see the discussion round including Mike Taylor; Taylor, 2012). In conclusion, it could be said that blog postings are no replacement for, but rather a useful adjunct to old-fashioned, peer-reviewed journal or book publications. Blog postings seem to already be on their trajectory to become a valuable part of the publication mix. (Cf. to the development around the project ScienceSeeker7.)
Wikis
While blog postings represent conclusive texts of individual authors, wikis are much more different from traditional ways of publishing. Wikis were initially introduced to document practices for developing software8, however, they became commonly known through the open and freely available online encyclopedia “Wikipedia” (wikipedia.org, since 2001). Wikis represent websites with content that can be collaboratively changed by potentially very large groups of users. Despite the fact that the usage of wikis grew far beyond the remit of software development and encyclopedias, Wikipedia significantly influenced the wide reception of wikis.
Wikis are hosted as open platforms in the public web. In most cases, a registration for the wiki is easily possible and new wiki topics can be proposed from anyone, while the triage of new articles or concurrent changes and their acceptation to the public version of wiki is done by the project founders or a special user group of the wiki. Usually, these are authors who have become especially trustworthy through their engagement with, or past contributions to the wiki. Usually the founding group provides style and content guidelines. Strict adherence to these guidelines is especially relevant since the content of articles is more or less implicitly approved of by all authors of the wiki community. To resolve disputes is particularly challenging since only one version of the articles exists. If disputes are unsolvable usually all views are elucidated and the reason for the dispute is mentioned.
The fact that many people can contribute to articles possesses the advantage that virtually anybody can become a co-author. Errors and biased viewpoints can be corrected much quicker than in traditional ways of publishing. This is under the assumption that all contributors adhere to the consensus of the wiki—potentially at the expense of personal writing styles and viewpoints.
The individual author has to accept that statements might be edited or modified by the community. Similarly, he has to accept its principles of meritocracy and the potential consequences that might arise from such principles.
On the other side, contributions to a continuously evolving wiki-project present the possibility of contributing to a work with an ongoing relevance. Even far into the future, relevant contributions by an individual author can be traced in detail in the revision history of the wiki text. This might also be used to scientometrically quantify the quality or relevance of contributions to wikis—for example current approaches include algorithmic modeling of the revision history (Kramer et al. 2008).
In contrast to scientific blogging and some dedicated wiki-projects, Wikipedia itself was never considered to be a platform to exchange originary research results. Wikipedia keeps an encyclopedic character, however, despite this, there are multiple examples of scientists who actively contribute to Wikipedia. Ever more so, some academic organizations propose a lively contribution to Wikipedia (Farzan & Kraut 2012).
A cointegration of a scientific journal and Wikipedia was started with Topic Pages by PLoS Computational Biology (Wodak et al. 2012). Topic Pages are a version of a page to be posted to (the English version of) Wikipedia. In other words, PLoS Computational Biology publishes a version that is static, includes author attributions, and is indexed in PubMed, all with the reviews and reviewer identities of Topic Pages available to the readership. The aim of this project is that the Wikipedia pages subsequently become living documents which will be updated and enhanced by the Wikipedia community.
Stack Exchange—message boards where threads are initiated by posting open questions
Question centered message boards (“stack exchange”) like MathOverflow and BioStar (Parnell et al. 2011) consists of comment threads that are posted under a known ID. A thread is centered on a question, which is in contrast to blogs which provide more or less opinions, reviews, comments, overviews, or novel hypotheses. A reputation (‘Karma’) can be built by earning ‘likes’ or ‘views’ from other users within the community (initially introduced by Slashdot in the 90s). The questioner and the community (Paul et al. 2012) assesses as to whether the answers are sufficient and whether the thread should be closed, maximizing the potential gain in Karma. The incentives set by this leads to many useful and comprehensible answers at the end of a good browseable question thread. Orienting threads around questions leads to a question-centered discussion and the discussions in turn stay on topic.
SNS for scientists
Social networking systems (SNS) have found widespread use in the Internet. Early examples are Friendster, Sixdegrees.com, Myspace, while Facebook made the concept widely available. In 2012 Facebook hit the first billion of users worldwide. After signing in to a SNS, users can set up a profile page with a multitude of information about themselves. Besides adopting the information, posting so-called ‘status updates’ has become very popular, ranging from personal feelings to more or less useful information on one’s current task or whereabouts, often together with some rich media such as pictures or movies.
Other users can follow the status update of particular members. Members that are ‘followed’ contribute to their own personal ‘timeline’—a collection of all status updates of fellow members. Other users can be added to the list of friends. Friending another user results in a mutual exchange of status updates, media, pictures, and many more things.
Usually, all friendship and follower connections are visible to a wider audience. This fact, together with many other aspects of proprietary SNS, resulted in privacy concerns which the provider tried to counteract by establishing selective privacy settings. Other SNS such as Twitter incorporated a full and mandatory openness into their strategy. With the advancement of SNS users are becoming more and more aware of the chances and dangers of SNS’s.
Most SNS’s create a rich social experience with a mixture of status updates from friends, personalized news, and the possibility of interacting with the postings of others by ‘liking’ or commenting on them. If the user decides that certain postings might be of interest to their friends or followers, they can share it with them—often with the click of a mouse button.
Dedicated SNS’s for scientists were established around 2008 (see chapter 07, Nentwich et al: Academia Goes Facebook? The Potential of Social Network Sites in the Scholarly Realm). Scientists started to share status updates related to their scientific work, in many cases information about published articles, abstracts, and talks. They provide a platform for users to post their research articles in compliance with copyright laws, since a profile page is considered to be a personal homepage (Green road to open access (see chapter 09, Sitek et al: Open Access: A State of the Art)). More and more often, scientists have started to take the opportunity to incorporate media as well as some interesting, novel findings into their status updates. The providers use information and connections between users to support scientists, using suggestions about interesting topics, other publications, and fellow researchers that work in similar fields. Mendeley, Academia.edu, and Researchgate.org have reached several millions of users.
Most users of SNS’s for scientists maintain a profile in a non-scientific SNS. At the dawn of the SNS, it seemed like there was only need for one SNS that could serve all personal, professional, and scientific (and many more) networking needs. However, this impression was wrong. It seems to be more suitable for users to maintain several profiles in several SNS’s, whereof the facets of the personal profile as well as the shared information depends on the purpose of the SNS (Nentwich et al. 2012). Users do not want to mix holiday pictures with their scientific publications.
In the past, SNS’s were not considered to be a means of sharing original scientific results. However, this may undergo profound changes. For example, in 2011, FigShare (a commercial service) was introduced, serving as a free repository for the archiving and presentation of scientific results. Researchgate as well as Mendeley allow the publication of preprints; Mendeley allows the finding of dedicated reviewers for certain publications.
SNS’s carry the potential of becoming a means of publishing scientific results in accordance with the ongoing decoupling of scientific communication channels from the journal system (???).
The status updates in SNS’s for scientists could be used to publish ideas, exciting findings, as well as links to other interesting sources. Commenting, as well as the ‘like’ functionality could act as a kind of peer-review. In SNS’s for scientists, status updates, comments, and likes are not anonymously done—therefore their creator together with their profile are visible to other scientists who can then assess the ‘credibility’ and the background of the contributing scientists. The ‘question’ functionality of ResearchGate provides a platform with vivid scientific discussions that were not possible in such a manner, were the users to hide behind anonymous acronyms.
Furthermore, SNS’s can analyze the activity of scientists and provide easily accessible, novel ‘impact’ metrics of scientists—based on their activity and reputation within a SNS or based on established metrics.
A SNS for scientists combined with a text editing and publishing platform might be the ideal platform to realize a dynamic publication system.
| Scholarly articles | Blogs / Microblogs | Wikis or other collaborative authoring tools | Social Coding / GitHub | |
| Application | One-time and nonrecurring release of a novel scientific finding | Irregular contributions, with novel findings, ongoing research and comments on third party findings | Collaborative writing, structuring of knowledge, work-flow processes, or as a tool to collaboratively prepare publication with several authors | Closed projects with a clear defined aim, e.g. producing a running computer code |
| ‘Reviewability’: Quality assurance and evaluation through others | Independent peer-review; retraction and comments only through publisher; comments; delayed assessment through citation data, in progressive journals usage statistics and altmetrics | Comments, usage data, social network metrics | A group of authors or a community releases and accepts novel content using a structured reviewing process, whereof the reviewing process is usually open; open comment functionality; usage data and social network metrics. | Usage data by tracking code pull requests; third party reuse |
| Continuity and integration with the scientific knowledge creation process | Referencing;Development of the article only during creation and peer-review process; Usually hidden from the public | Serial publishing of novel contribution; links to other blog posts/articles; comments and trackbacks allow dynamic interaction | Continuous collaborative creation and changing of content; history function available | Continuous working as a team on a common project; results can be reused by other projects |
| Authorship and accountability of contributions | Authors provide information about their contribution; author position is negotiated | Usually the blogger is the only author | Exact labelling of the contribution, independent from size | Exact labelling of the contribution, independent from size |
| Collaborative content control | The content is provided only by the authors; content and relevance controlled by the editorial board of the journal | Single author is responsible for content; commenting is allowed | Wide consent on the scope of the project; conflicts will be addressed and solved by majority decisions; everybody can contribute | ‘Maintainer’ decides about acceptance or rejection of changes; if conflicts exists, project can be divided into two sub projects (‘forking’) |
| Technical reusability | Potentially possible, but practically limited by PDF format; little use of markup languages and remixing mechanisms such as “forking” or “transclusion” | Usage of markup languages including HTML; but no implementation of remixing or forking mechanisms | Highly reusable; content is highly structured; flexible markup language; transclusion within the platform; easily traceable transclusion | Highly reusable; examples for usage of markup languages such as Markdown and Pandoc for text publications; forks easily and often done; traceable |
| Legal reusability | More and more use of more open copyright licenses; | Almost only use of open copyright licenses that allow reuse | Very high; wikipedia-like or creative commons licenses | Very high; free licenses that allow reuse |
| Implementations | Proprietary journal platforms or open journal platforms such as Open Journal System of public knowledge project (see chapter 11) | WordPress with wide spread use; other blogging solutions | MediaWiki with wide spread use; proprietary tools such as Google Docs | GitHub or free repository platform Git; Sourceforge or CVS |
| History function | Traces of creation process usually deleted; no history function | No traces of creation process; no history function | Complete traces of creation process and history of articles; seamless traces of discussion | Complete traces of creation process and history of articles; seamless traces of discussion |
| Openness, in general | Closed, after publication after paywall/open access | Closed until publication than open | Form very beginning open to a wide community | Form very beginning open to a wide community |
| Readability in style / Redundancy: 1. In the best case | Ability to frame a finished research result, in homogenous writing style by one (or a few) author(s). | Direct reporting of research results with readability of (good) science journalism. | Capacity for continuous refinement and correction of text; authors allowed to remix / translate from previously existing articles. | Capacity for continuous refinement and correction of text. |
| Readability in style / Redundancy: 2. Challenges and problems | External pressures to ‘publish or perish’ and therefore diluted and dispersed results. | Often “serialized” reporting of ongoing, not yet finished research. As such mostly addressing peers in same research topic area (e.g. by not making clear research aims, presumptions, methods used, etc. in each new blog post). | Hard to maintain consistent encyclopaedia-level content and readability with large author community. In addition, this often leads to wiki-bureaucracy, e.g. meta-level of templates, rules, acceptance of proposed changes, etc. | At present, few experiences with article-style collaborative knowledge production in code repositories; by now mostly used for production / collection / integration of code and data. |
| Compared e.g. to wiki / social coding writing style: unusual to “remix” previously existing text and/or make later corrections in style. | ||||
| Acceptance within scientific community | Together with books in most disciplines the essential part of scientific publishing; officially credited | Somewhat accepted, but most often not credited | Widely used, but contribution not credited | Used, e.g. for production and maintenance of software code, in some cases data collections / documentation; Most often not credited |
References
Efimova, L., 2009. Passion at work: blogging practices of knowledge workers. Enschede: Novay. Available at: http://blog.mathemagenic.com/phd/dissertation/.
Farzan, R. & Kraut, R., 2012. Eight Months of APS Wikipedia Initiative. Available at: http://de.slideshare.net/PsychScience/recruiting-and-engaging-psychologists-to-the-aps-wikipedia-initiative.
Kramer, M., Gregorowicz, A. & Iyer, B., 2008. Wiki trust metrics based on phrasal analysis. In ACM Press, p. 1. doi:10.1145/1822258.1822291.
Mietchen, D., Hagedorn, G. & Förstner, K.U., 2011. Wikis in scholarly publishing. Information Services and Use, 31(1-2), pp.53–59. doi:http://dx.doi.org/10.3233/ISU-2011-0621.
Parnell, L.D. et al., 2011. BioStar: An Online Question & Answer Resource for the Bioinformatics Community P. E. Bourne, ed. PLoS Computational Biology, 7(10), p.e1002216. doi:10.1371/journal.pcbi.1002216.
Paul, S.A., Hong, L. & Chi, E.H., 2012. Who is Authoritative? Understanding Reputation Mechanisms in Quora. In Collective Intelligence conference. doi:arXiv:1204.3724.
Pochoda, P., 2012. The big one: The epistemic system break in scholarly monograph publishing. New Media & Society. doi:10.1177/1461444812465143.
Pöschl, U., 2012. Multi-Stage Open Peer Review: Scientific Evaluation Integrating the Strengths of Traditional Peer Review with the Virtues of Transparency and Self-Regulation. Frontiers in Computational Neuroscience, 6. doi:10.3389/fncom.2012.00033.
Rice, C., 2013. Science research: three problems that point to a communications crisis. theguardian. Higher Education Network. Available at: http://www.guardian.co.uk/higher-education-network/blog/2013/feb/11/science-research-crisis-retraction-replicability.
Schneider, J., 2011. Beyond the PDF. Ariadne, 66(January). Available at: http://www.ariadne.ac.uk/issue66/beyond-pdf-rpt.
Taylor, M., 2012. What is the difference between a paper and a blog post? Sauropod Vertebra Picture of the Week. Available at: http://svpow.com/2012/10/14/what-is-the-difference-between-a-paper-and-a-blog-post/.
Wodak, S.J. et al., 2012. Topic Pages: PLoS Computational Biology Meets Wikipedia. PLoS Computational Biology, 8(3), p.e1002446. doi:10.1371/journal.pcbi.1002446.
Nentwich, M. et al., 2012. Cyberscience 2.0: Research in the age of digital social networks, Frankfurt; New York: Campus Verlag.
Wikiversity: http://en.wikiversity.org/wiki/Wikiversity:Journal_of_the_future↩
A concept derived from software development, but also applicable to texts, see Wikipedia↩
journalists of the New York Times in 19. century stated “All the news that’s fit to print” (cf. Encyclopædia Britannica Online: http://www.britannica.com/EBchecked/topic/850457/All-the-News-Thats-Fit-to-Print)↩
Ward Cunningham: http://de.wikipedia.org/wiki/Ward_Cunningham; Wiki Wiki Web: http://c2.com/cgi/wiki?WikiWikiWeb↩
Next chapter: Open Research Data: From Vision to Practice
Heinz Pampel & Suenje Dallmeier-Tiessen